

Recently, I have been working on the Neural Networks for Machine Learning course offered by Coursera and taught by Geoffrey Hinton. Overall, it is a nice course and provides an introduction to some of the modern topics in deep learning. However, there are instances where the student has to do lots of extra work in order to understand the topics covered in full detail.
One of the assignments in the course is to study the Neural Probabilistic Language Model (The related article can be downloaded from here). An example dataset, as well as a code written in Octave (equivalently Matlab) are provided for the assignment. While the assignment itself is easily completed by filling in some lines of code, it took me a while and some paper and pen calculations to figure out what the code is exactly doing. Therefore, I thought that it would be a good idea to share the work that I did in this post. Below is a short summary, but the full write-up contains all the details.
Short Description of the Neural Language Model
Given a sequence of D words in a sentence, the task is to compute the probabilities of all the words that would end this sentence. The words are chosen from a given vocabulary (V). Namely, one needs to compute the following conditional probability:

for any given example (i). Each word is represented by a vector w, which has the dimension of the dictionary size (|V|). For example, consider the sentence:
“We all have it”
In this case D=3. Given {We, all, have} we need to compute the probability of getting {it} as the 4th word. Each word has an index in the vocabulary. For example:
{We = 91}, {all = 1}, {have = 3}, {it = 181}
which translates to the word vectors w as follows: w1 representing “We” will be a |V| dimensional vector with the entry 91 being equal to 1, and all other entries equal to 0. Similarly, w2 representing “all” will have its 1st entry equal to 1 and all others 0 etc.
A neural network would require an input layer with the size of the vocabulary, which could be very large. A traditional network would also require a huge number of neurons to calculate the probabilities, which would lead to a very large number parameters to be optimized. To avoid over-fitting, one needs a giant dataset for training which could make the problem intractable. This problem (a.k.a curse of dimensionality) can be circumvented by introducing word embeddings through the construction of a lower dimensional vector representation of each word in the vocabulary. This approach not only addresses the curse of dimensionality, but also results in an interesting consequence: Words having similar context turn out to have embedding vectors close to each other. For instance, the network would be able to generalize from
“The cat is walking in the bedroom”
to
“A dog is running in a room”
since “cat” – “dog”, “walking” – “running” , “bedroom” – “room” have similar contexts thus they are close to each other in the space of word embedding vectors. A more detailed discussion can be found in the Bengio et al.’s article. I will spend the rest of the post to the architecture of the network that achieves this goal and some implementation details.
The Network Architecture
The structure of the neural network is schematically shown below.

The input layer contains the indices of the words from the vocabulary and there are D of them (since a training example has D words, and the task is to predict the word D+1 to finish the sentence). The second layer is the embedding layer, and transforms each input word (that has the dimension of the vocabulary |V|), into a lower dimensional vector representation (say h1). There is one hidden layer with size h2, and the output layer has size |V| which is then fed into a softmax function to compute the probability of each word in the vocabulary.
The embedding layer deserves some more explanation. Passing from the input to the embedding layer, one obtains an embedding vector for each of the D words that are stacked together to form the (D . h1) dimensional vector (a1):
 Here, the embedding weights (C) are shared among all the D words. In passing from the input layer with word indices to the embedding layer resulting in a1, the operation shown above is a table lookup. Namely, for each given word index, one needs to find out which row in C its embedding is located. To make it clearer, let’s consider an example. Suppose we have a training batch with D=3 stacked in a matrix as follows:
Here, the embedding weights (C) are shared among all the D words. In passing from the input layer with word indices to the embedding layer resulting in a1, the operation shown above is a table lookup. Namely, for each given word index, one needs to find out which row in C its embedding is located. To make it clearer, let’s consider an example. Suppose we have a training batch with D=3 stacked in a matrix as follows:
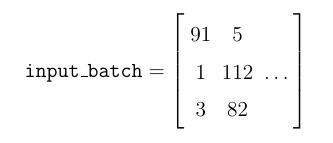
Each column represents a training example: The 1st column represents the words “We, all, have” given above. Given the word embeddings C (determined through the training process), the table lookup involves unfolding the input_batch into a vector and subsetting the rows of C corresponding to each word in the vocabulary. Namely,
 Now that the embedding vectors are obtained, we can feed forward through the network to compute probabilities.
Now that the embedding vectors are obtained, we can feed forward through the network to compute probabilities.
Forward Propagation and Probabilities
The rest of the process is pretty straightforward and follows the standard forward propagation for any neural network. At the end, one obtains an output vector y, which is the unnormalized log-probabilities for each word in the vocabulary. Once this vector is fed into a softmax function (shown in the figure above), the word probabilities are obtained: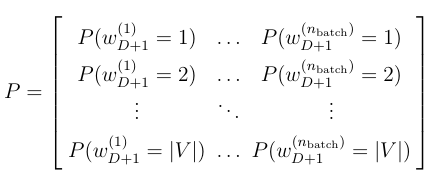
Of course, this process (along with backpropagation) has to be repeated many epochs during the optimization of the weights (C,W1,W2) and biases (b1,b2) in the network. The loss function which is used for optimization is the negative log-likelihood obtained from the above computed probabilities:
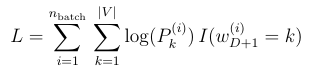
Here, the term (I) multiplying the log probabilities constrain the sum so that whenever the index of the word in the training data meets with its location in the vocabulary, this term gives 1, otherwise it gives 0.
Back Propagation and Computation of Gradients
This is the final step in training the neural network. Backpropagation is used to compute the gradients of the loss function with respect to the parameters (C, W1, W2, b1, b2) of the neural network. These gradients are then used in an optimization algorithm, e.g. batch gradient descent, for training the network. The derivation of the backpropagation rules can get a little tedious, especially for the gradient with respect to the embedding weights C. I therefore refer the interested reader to the full write-up that I have put together, which explains both the mathematics and the implementation of backpropagation in detail.

2 Comments